Computer Science is a research that explores the detection, representation, and extraction of useful data information. It is gathered by data analyst from different sources to be used for business purposes.
With a vast amount of facts producing every minute, the necessity for businesses to extract valuable insights is a must. It helps them to stand out in the crowd. Many professionals are taking their founding steps in data science, with the enormous demands for data scientists. Despite a large number of people being inexperienced in data science, young data analysts are making a lot of simple mistakes.
The concept of data analytics encompasses its broad field reach as the process of analyzing raw data to identify patterns and answer questions. It does, however, include many strategies with many different objectives.
The process of data analytics has some primary components which are essential for any initiative. A useful data analysis project would have a straightforward picture of where you are, where you were, and where you will go by integrating these components.
This cycle usually begins with descriptive analytics. That is the process of describing historical data trends. Descriptive analytics seeks to address the “what happened?” question. It also has assessments of conventional metrics like investment return (ROI). Of each industry, the metrics used would be different. Descriptive analytics does not allow forecasts or notify decisions directly. It focuses on the accurate and concise summing up of results.
Advanced analytics is the next crucial part of data analytics. This section of data science takes advantage of sophisticated methods for data analysis, prediction creation, and trend discovery.
This data provides new insight from the data. Advanced analytics answers, “what if? “You have concerns.
The availability of machine learning techniques, large data sets, and cheap computing resources has encouraged many industries to use these techniques. Big data sets collection is instrumental in allowing such methods. Big data analytics helps companies to draw concrete conclusions from diverse and varied data sources that have made advances in parallel processing and cheap computing power possible.
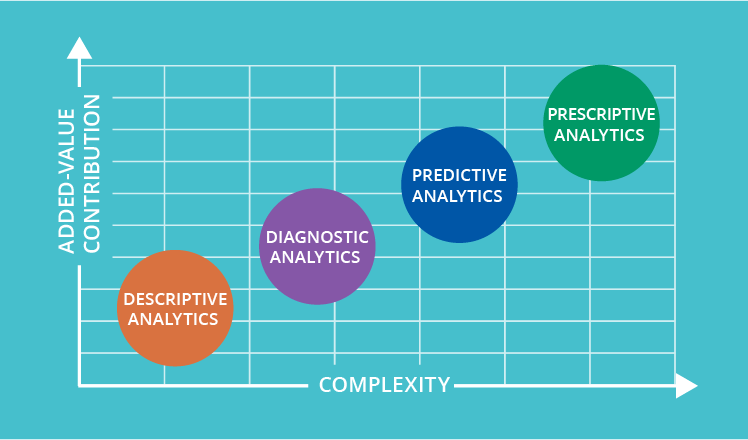
Data analytics is an extensive field. Four key data analytics types exist descriptive, analytical, predictive, and prescriptive analytics. Each type has a different objective and place in the process of analyzing the data. These are also the primary applications in business data analytics.
Descriptive analytics helps to address concerns about what happened. These techniques sum up broad datasets to explain stakeholder outcomes. Such methods can help track successes or deficiencies by creating key performance indicators ( KPIs). In many industries, metrics like return on investment ( ROI) are used. Specific parameters for measuring output are built in different sectors. This process includes data collection, data processing, data analysis, and visualization of the data. This process provides valuable insight into past success.
Diagnostic analytics help address questions as to why things went wrong. These techniques complement more fundamental descriptive analytics. They are taking the findings from descriptive analytics and digging deeper for the cause. The performance indicators will be further investigated to find out why they have gotten better or worse. That typically takes place in three steps:
Predictive analytics aims to address concerns about what’s going to happen next. Using historical data, these techniques classify patterns and determine whether they are likely to recur. Predictive analytical tools provide valuable insight into what may happen in the future, and their methods include a variety of statistical and machine learning techniques, such as neural networks, decision trees, and regression.
Prescriptive analytics assists in answering questions about what to do. Data-driven decisions can be taken by using insights from predictive analytics. In the face of uncertainty, this helps companies to make educated decisions. The techniques of prescriptive analytics rely on machine learning strategies, which can find patterns in large datasets. By evaluating past choices and events, one can estimate the probability of different outcomes.
Such types of data analytics offer insight into the efficacy and efficiency of business decisions. They are used in combination to provide a comprehensive understanding of the needs and opportunities of a company.

It should come as no surprise that there is one significant skill the modern marketer needs to master the data. As growth marketers, a large part of our task is to collect data, report on the data we’ve received, and crunched the numbers to make a detailed analysis. The marketing age of gut-feeling has ended. The only way forward is by skillful analysis and application of the data.
But to become a master of data, it’s necessary to know which common errors to avoid. We ‘re here to help; many advertisers make deadly data analysis mistakes-but you don’t have to!
In statistics and data science, the underlying principle is that the correlation is not causation, meaning that just because two things appear to be related to each other does not mean that one causes the other. It is the most common mistake apparently in the Time Series. Fawcett gives an example of a stock market index, and the media listed the irrelevant time series Amount of times Jennifer Lawrence. Amusingly identical, the lines feel. A statement like “Correlation = 0.86” is usually given.
Note that a coefficient of correlation is between +1 (perfect linear relationship) and -1 (perfectly inversely related), with zero meaning no linear relation. 0.86 is a high value, which shows that the two-time series statistical relationship is stable.
Some data analysts and advertisers analyze only the numbers they get, without placing them into their context. If that is known, quantitative data is not valid. For these situations, whoever performs the data analysis will ask themselves “why” instead of “what.” Fallen under the spell of large numbers is a standard error committed by so many analysts.
In data science, this can be seen as the tone of the most fundamental problem. Most of the issues that arise in data science are because the problem is not defined correctly for which solution needs to be found. If you can’t describe the problem well enough, then it would be a pure illusion to arrive at its solution. One will adequately examine the issue and evaluate all components, such as stakeholders, action plans, etc.
When you are just getting started, focusing on small wins can be tempting. Although it’s undoubtedly relevant and a fantastic morale booster, make sure it doesn’t distract you from other metrics that you can concentrate more on (such as revenue, customer satisfaction, etc.
Always assume at first that the data you are working with is inaccurate. When you get acquainted with it, you can start to “ feel ”when something is not quite right. Use pivot tables or fast analytical tools to look for duplicate records or incoherent spelling first to clean up your results. Furthermore, not standardizing the data is just another issue that can delay the research. In most cases, you remove the units of measurement for data while normalizing data, allowing you to compare data from different locations more easily.
Outliers that affect any statistical analysis, therefore, analysts should investigate, remove, and real outliers where appropriate. The decision on how to handle any outliers should be reported for auditable research. Often the loss of information in exchange for improved understanding may be a fair trade-off.
For some instances, many people fail to consider the outliers that have a significant impact on the study and distort the findings. In certain other situations, you might be too focused on the outliers. Despite this, you devote a great deal of time to dealing with things that might not be of great significance in your study.
Let’s take the Pie Charts scenario here. Pie charts are meant to tell a narrative about the part-to-full portion of a data collection. That is, how big part A is regarding part B, part C, and so on. The problem with pie charts is that they compel us to compare areas (or angles), which is somewhat tricky. Experience comes with choosing the best sort of graph for the right context.
Someone shouldn’t rely too much on their model’s accuracy to such a degree that you start overfitting the model to a particular situation. Analysts create machine learning models to refer to general scenarios. Overfitting a pattern can just make it work for the situation that is the same as that in preparation. In this case, for any condition other than the training set, the model would fail badly.
Holidays, summer months, and other times of the year get your data messed up. Thanks to the busy tax season or back-to-school time, also a 3-month pattern is explainable. Make sure that you consider some seasonality in your data … even days of the week or daytime!
Establishing the campaigns without a specific target will result in poorly collected data, incomplete findings, and a fragmented, pointless report. Do not dig into your data by asking a general question, “how is my website doing?”
Alternatively, continue your campaigns on a simple test hypothesis. Place clear questions on yourself to explain your intentions. Determine your Northern Star metric and define parameters, such as the times and locations you will be testing for. For example, ask, “How many views of pages did I get from users in Paris on Sunday? “Gives you a simple comparable metric.
If you conclude a set of data that is not representative of the population you are trying to understand, sampling bias is.
You might run a test campaign on Facebook or LinkedIn, for instance, and then assume that your entire audience is a particular age group based on the traffic you draw from that test. But if you were to run the same Snapchat campaign, the traffic would be younger. In this case, the audience’s age range depends on the medium used to convey the message-not necessarily representative of the entire audience.
Comparing different data sets is one way to counter the sampling bias. However, make sure you avoid unfair comparison when comparing two or more sets of data.
Unequal contrast is when comparing two data sets of the unbalanced weight. One typical example of this is to compare two reports from two separate periods. They may be a month over month, but if they fail to consider seasonality or the influence of the weekend, they are likely to be unequal. For example, during December, web traffic for an eCommerce site is expected to be affected by the holiday season. It thus cannot be directly compared to the traffic numbers from March.
Let’s be frank; advertisers are using quite a lot of jargon. Even if you’ve been in the game for a while, metrics can be curiously labeled in various ways, or have different definitions. When you don’t, it’s easy to assume you understand the data.
A clear example of this is the bounce rate. As we asked a group of advertisers recently, they all concluded that the bounce rate was tourists leaving the web too fast.
It is simply incorrect – the percentage of visitors who move away from a site after visiting only one page is bounce rate. And this doesn’t necessarily mean a high bounce rate is a negative thing. You may assume, for example, that your bounce rate on a site with only a few pages is high.
This is an easy one to fall for because it can affect various marketing strategies. Let’s say you launched a campaign on Facebook, and then you see a sharp increase in organic traffic. You could, of course, conclude that your campaign on Facebook drive traffic to your eyes.
This inference may not be accurate, and believing that one activity is induced directly by another will quickly get you into hot water. Sure, there may be similarities between the two phenomena. Yet another initiative can also be responsible for the rise in traffic, or seasonality, or any of several variables.
Just as old-school sailors looked to the Northern Star to direct them home, so should your Northern Star Metric be the “one metric that matters” for your progress. That means the one metric which accurately measures the performance at which you are aiming. All other metrics that you keep track of will tie back to your star in the north.
So be careful not to get caught in a sea of meaningless vanity metrics, which does not contribute to your primary goal of growth. Distracting is easy, mainly when using multiple platforms and channels. Stick to the fundamental measure and concentrate only on the metrics that specifically impact it.
Let’s say you have a great set of data, and you have been testing your hypothesis successfully. It may be tempting, but don’t make the mistake of testing several new hypotheses against the same data set.
Although this can seem like a convenient way to get the most out of your work, any new observations you create are likely to be the product of chance, since you’re primed to see links that aren’t there from your first product. These are not meaningful indicators of coincidental correlations.
An excellent way to avoid that mistake is to approach each set of data with a bright, fresh, or objective hypothesis. And, when the theory shifts, a new collection of data refreshes the analysis.
As marketers for production, we are always looking for validation of the results. Statistics give us confidence-they are objective. They’re giving us some quantitative realities. But it can be misleading to rely too much on raw numbers, also. It’s like not looking through the trees at the wood. Marketers who concentrate too much on a metric without stepping back may lose sight of the larger image.
If your organic traffic is up, it’s impressive, but are your tourists making purchases? Your presence on social media is growing, but are more people getting involved, or is it still just a small community of power users? To get the full picture, it’s essential to take a step back and look at your main metrics in the broader context.
You’ve run a check, collected the data, and you’ve got a definite winner. Yet make sure you don’t draw your conclusions too early without some apparent statistical validity.
This error is standard when running A / B conversion tests, where the results may at first seem obvious, with one test outperforming another. However, it is necessary not to rush too early to a conclusion.
To classify the winning variant, make sure you have a high likelihood and real statistical significance. For example, we suggest a 96 percent likelihood and a minimum of 50 conversions per variant when conducting A / B tests to determine a precise result.
Marketers are busy, so it is tempting only to give a short skim to the data and then make a decision. By offering summary metrics, which are averages of your overall metrics, most platforms allow this sort of thinking.
But decision-making based on summary metrics is a mistake since data sets with identical averages can contain enormous variances. For four weeks straight, your Google Ad might get around 2,000 clicks a week, but that doesn’t mean that those weeks are comparable, or that customer behavior was the same. To determine the correct response to your Google Ad, you will need to look at the full data sets for each week to get an accurate picture of the behavior of the audience.
Cross-platform marketing has become critical as more consumers gravitate to the web. But, it can present significant challenges.
Mobile and desktop need separate strategies, and thus similarly different methodological approaches. Make no mistake to merely merge the data sets into one pool and evaluate the data set as a whole.
Users behave differently on conventional computers and mobile devices, and their data should be kept separate for proper analysis to be carried out. Through this way, you will gain the information you would otherwise lack, and get a more accurate view of real consumer behavior.
Although Malcolm Gladwell may disagree, outliers should only be considered as one factor in an analysis; they should not be treated as reliable indicators themselves. This is because web data is complex, and outliers inevitably arise during the information mining process.
The typical response is to disregard an outlier as a fluke or to pay too much attention as a positive indication to an outer. The reality usually lies somewhere in the middle as in other stuff.
For example, excusing an unusual drop in traffic as a seasonal effect could result in you missing a bigger problem.
Overfitting is a concept that is used in statistics to describe a mathematical model that matches a given set of data exactly. It defines a model that does a decent job of explaining the current data set on hand but fails to forecast trends for the future. This is too tightly related to exact numbers without reflecting on the data series as a whole.
The marketers are continually falling prey to this thought process. Be sure to consider the broader, overarching behavior patterns your data uncovers when viewing your data, rather than attempting to justify any variation. Keep templates simple and flexible.
Getting inadequate knowledge of the business of the problem at hand or even less technical expertise required to solve the problem is a trigger for these common mistakes. Appropriate market views, target, and technological knowledge must be a prerequisite for professionals to begin hands-on.
Less time for the end review will hurry the analysts up. This results in analysts losing small information as they can never follow a proper checklist and hence these frequent errors.
Information science is a vast topic, and having full knowledge of data science is a very uphill challenge for any fresher. Common errors in data science result from the fact that most professionals are not even aware of some exceptional data science aspects.
Data mining is both an art as well as a science. You need to be both calculative and imaginative, and it will pay off your hard efforts. There’s nothing more satisfying than dealing with and fixing a data analysis problem after multiple attempts. If you do get it right, the benefits to you and the company will make a big difference in terms of saved traffic, leads, sales, and costs.
A data analyst’s job includes working with data across the pipeline for the data analysis. It means working in various ways with the results. Data mining, data management, statistical analysis, and data presentation are the primary steps in the data analytics process. The value and equilibrium of these measures depend on the data being used and the research purpose.
Software mining is an essential method for many activities related to data processing. That includes extracting data from unstructured sources of data. It may involve written text, large complex databases, or raw data from sensors. The main phases of this method are the extraction, transformation, and loading of data (often called ETL).
Another essential part of the work of a data analyst is data storage or data warehousing. Data warehousing involves the design and implementation of databases that allow easy access to data mining results. In general, this step includes the development and management of SQL databases. Non-relational databases and NoSQL databases are also getting more frequent.
Data mining is the heart of statistical research. It is how data produces knowledge. Data are analyzed using both statistics and machine-learning techniques. Big data is used to generate mathematical models that reveal data trends. Then, these models can be applied to new data to predict and guide decision making.
For this method, statistical programming languages such as R or Python (with pandas) are essential. Additionally, open-source libraries and packages like TensorFlow allow for advanced analysis.
The final step in most processes of data processing is the presentation of the results. It is a crucial move allowing for the exchange of knowledge with stakeholders. The most critical method of data analysis is also data visualization. Compelling visualizations are essential for communicating the story in the data that may help managers and executives appreciate the importance of these insights.
Looking for a data analyst? If yes, contact us today.

You must be logged in to post a comment.






Great article. I will definitely apply this from today.
Perfect piece of work you have done. Great information!
Great article! Got to learn a lot.
The written content is real good!