
Most of us nowadays are focused on building machine learning models and solving problems with the existing datasets. But we need to first understand what a dataset is, its importance, and its role in building robust machine learning solutions. Today we have an abundance of open-source datasets to do research on or build an application to solve real-world problems in many fields.
However, the lack of quality and quantitative datasets are a cause of concern. Data has grown tremendously and will continue to grow at a higher pace in the future. So, how do we use the huge volumes of data in AI research? Here we will discuss ways to smartly leverage the existing dataset or generate the right datasets for the given requirements.
What is a Dataset in Machine Learning?
Dataset is a collection of various types of data stored in a digital format. Data is the key component of any Machine Learning project. Datasets primarily consist of images, texts, audio, videos, numerical data points, etc., for solving various Artificial Intelligence challenges such as
- Image or video classification
- Object detection
- Face recognition
- Emotion classification
- Speech analytics
- Sentiment analysis
- Stock market prediction, etc.

Why is Dataset Important?
We can not have an Artificial Intelligence system with data. Deep Learning models are data-hungry and require a lot of data to create the best model or a system with high fidelity. The quality of data is as important as the quantity even if you have implemented great algorithms for machine learning models. The following quote best explains the working of a machine learning model.
Garbage In Garbage Out (GIGO): If we feed low-quality data to ML Model it will deliver a similar result.
According to The State of Data Science 2020 report, data preparation and understanding is one of the most important and time-consuming tasks of the Machine Learning project lifecycle. Survey shows that most Data Scientists and AI developers spend nearly 70% of their time analyzing datasets. The remaining time is spent on other processes such as model selection, training, testing, and deployment.

Limitation of Datasets
Finding a quality dataset is a fundamental requirement to build the foundation of any real-world AI application. However, the real-world datasets are complex, messier, and unstructured. The performance of any Machine Learning or Deep Learning model depends on the quantity, quality, and relevancy of the dataset. It’s not an easy task to find the right balance.
We are privileged to have a large corpus of open-source datasets in the last decade which has motivated the AI community and researchers to do state-of-the-art research and work on AI-enabled products. Despite the abundance of datasets, it is always a challenge to solve a new problem statement. The following are the prominent challenges of datasets that limit data scientists from building better AI applications.
- Insufficient Data – Non-availability of large samples of data points required by Machine Learning algorithms.
- Bias and Human Error – Most tools used for data collection lead to either human error or bias towards one aspect.
- Quality – The real-world datasets are unorganized and complex. They are of low quality almost by default.
- Privacy and Compliance – Most sources do not share their data due to some privacy and compliance regulations. For example medical, national security, etc.
- Data Annotations Process – Generally human interventions are used to manually label datasets for quality, which results in an error. It is time-consuming and expensive.
How to Build Datasets for Your Machine Learning Projects?
An Artificial Intelligence application flow is depicted in the diagram below. The first two components are the dataset acquisitions & data annotation section which are crucial to understanding for building a good Machine Learning application.
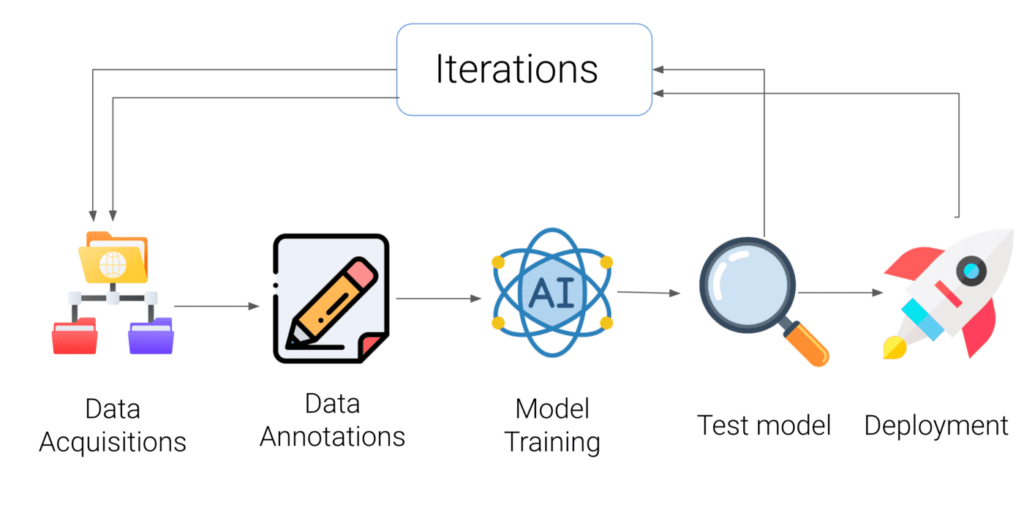
Nowadays, we have ample resources where we can get datasets on the internet either open-source or paid. As you know data collection and preparation is the crux of any Machine Learning project, and most of our precious time is spent on this phase.
To solve the problem statements using Machine Learning, we have two choices. Either we use the existing datasets or create a new one. For a highly specific problem statement, you have to create a dataset for a domain, clean it, visualize it, and understand the relevance to get the result. However, if the problem statement is common, you can use the following dataset platforms for research and gather data that best suits your requirements.
Actionable Advice for Data-Driven Leaders
Struggling to reap the right kind of insights from your business data? Get expert tips, latest trends, insights, case studies, recommendations and more in your inbox.
Best Dataset Search Engine Platforms for a Machine Learning Challenge
Below is the list of a few dataset platforms, that allow us to search and download data for Machine Learning projects and experiments. Most of the datasets are already cleaned and segregated for ML and AI project pipeline. However, we have to filter and utilize them according to our specifications.
- Google Dataset Search Engine
- Kaggle Datasets
- ZDataset Free -Dataset
- UCI Machine Learning Repository
- ICPSR Datasets
- Data World
- gesisDataSearch
- UK Dataservice
Custom Dataset can be created by collecting multiple datasets. For example, if we want to build an app to detect kitchen equipment, we need to collect and label images of relevant kitchen equipment. For labeling the images, we can run a campaign to collect data by encouraging users to submit or label images on a platform. They can be paid or rewarded for the task. Here are a few options that can be used to get data quickly for your requirements.
- Generate real-world datasets by creating a mobile app to capture images or use an existing app.
- Create a web app, and a single page, and plug it into your website. Ask users to annotate data for rewards. (open-source frameworks, for instance, audio collection for ASR applink /code.)
- Build an in-house team to compile a dataset.
- The Amazon Mechanical Turk is also a great option for crowdsourcing tasks for minimal charges.
- Hire research community students or volunteers to take part in data collection.
- Sign an agreement with data providers for the acquisitions of sensitive datasets like Medical health records (EHR datasets), X-rays or MRIs, etc. Generally, hospitals tie-up with research institutes for such projects.
A synthetic dataset is created using computer algorithms that mimic real-world datasets. This type of dataset has shown promising results in the experiments conducted to build Deep Learning models to create more generalized AI systems. Different techniques can be leveraged to generate a dataset.
Nowadays, researchers and developers utilize game technology to render realistic scenarios. Game framework unity is used to create datasets of particular interest and then used in the production of real-world data. Unity report shows that the synthesized dataset can be used to improve models’ performance. For instance, computer vision models use synthetic images to iterate fast experiments and enhance accuracy.
Generative Adversarial Networks (GANs) are also used to create synthetic datasets. These are neural network-based model architectures used for generating realistic datasets. Most use case requires data privacy and confidentiality. Hence, these networks are utilized to generate a sensitive dataset that is hard to acquire or collect from public sources.
Data Augmentation is widely used by altering the existing dataset with minor changes to its pixels or orientations. It’s helpful when we are out of data to feed our Neural Network. However, we cannot apply the augmentation technique to every use case as it may alter the real result output. For instance, in the medical domain dataset, we cannot augment more data from the raw source as it’s case sensitive and may end up generating irrelevant data. This will hamper our model and cause more trouble. Some widely used augmentation techniques are :
- Padding
- Random rotating
- Re-scaling
- Vertical and horizontal flipping translation
- Cropping
- Zooming
- Darkening & brightening/color, etc.

Conclusion
Data has come along a long way in the past few years, from countable numbers to now sitting on countless data points. Data is generated at a faster pace than ever. But, we can control the quality of data points, which will lead to the success of our AI models.
Datasets are, after all, the core part of any Machine Learning project. Understanding and choosing the right dataset is fundamental for the success of an AI project.


















